Organizations rely heavily on efficient data integration practices to make informed decisions, drive business growth, and stay competitive. Two popular data integration approaches have emerged: Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT). While both methods have been widely adopted, they differ significantly in their approach, advantages, and use cases. In this blog, we will explore ETL and ELT, and their differences, benefits, and drawbacks, to help you determine which approach is best suited for your organization’s data integration needs.
ETL: The Traditional Approach
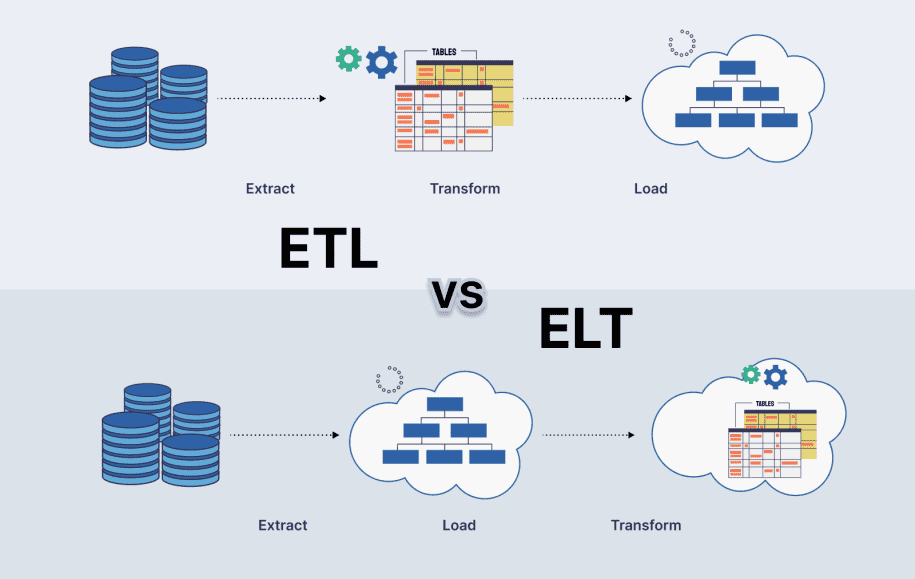
ETL is a well-established data integration method that has been widely used. The process involves three stages:
1. Extract: Data is extracted from various sources, such as databases, files, or applications.
2. Transform: The extracted data is transformed into a standardized format, which includes data cleansing, aggregation, and formatting.
3. Load: The transformed data is loaded into a target system, such as a data warehouse, data mart, or data lake.
ETL is commonly used for batch processing, where large volumes of data are processed in a single operation. This approach is suitable for organizations with well-defined data structures and schemas, where data is primarily used for reporting and analysis.
ELT: The Modern Alternative
ELT is a more recent data integration approach that has gained popularity with the rise of big data and cloud computing. The process involves three stages:
1. Extract: Data is extracted from various sources, similar to ETL.
2. Load: The extracted data is loaded into a target system, such as a data lake or cloud storage.
3. Transform: The loaded data is transformed into a standardized format, which includes data cleansing, aggregation, and formatting.
ELT is designed for real-time data processing, where data is constantly being generated and needs to be processed immediately. This approach is suitable for organizations with large volumes of unstructured or semi-structured data, where data is primarily used for analytics, machine learning, and data science.
Key Differences
The main differences between ETL and ELT lie in the order of operations and the processing approach:
Processing Order: ETL processes data in a linear fashion, where data is extracted, transformed, and then loaded. ELT, on the other hand, loads data first and then transforms it.
Processing Approach: ETL is designed for batch processing, while ELT is designed for real-time processing.
Advantages and Disadvantages
Both ETL and ELT have their advantages and disadvantages:
ETL Advantages
Maturity: ETL is a well-established approach with a wide range of tools and expertise available.
Data Quality: ETL ensures high data quality through rigorous data transformation and cleansing.
Scalability: ETL can handle large volumes of data and is suitable for batch processing.
ETL Disadvantages
Complexity: ETL requires complex data transformation and mapping, which can be time-consuming and resource-intensive.
Inflexibility: ETL is less flexible than ELT, as it requires a predefined data structure and schema.
Cost: ETL can be costly, especially for large-scale implementations.
ELT Advantages
Flexibility: ELT is more flexible than ETL, as it can handle unstructured and semi-structured data.
Real-time Processing: ELT enables real-time data processing, making it suitable for applications that require immediate data insights.
Cost-Effective: ELT can be more cost-effective than ETL, as it eliminates the need for complex data transformation and mapping.
ELT Disadvantages
Immaturity: ELT is a relatively new approach, and the tools and expertise are still evolving.
Data Quality: ELT may compromise on data quality, as data is loaded before transformation and cleansing.
Scalability: ELT can be challenging to scale, especially for large volumes of data.
Criteria | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
Processing Location | Transformation occurs in an intermediate server before data is loaded into the target system. | Transformation is handled within the target system (e.g., data warehouse or data lake). |
Target System Compatibility | Typically designed for on-premises databases and traditional data warehouses. | Optimized for modern cloud-based data warehouses and big data environments. |
Data Staging | Uses staging areas to temporarily store and process data before loading it into the target system. | Avoids staging areas; raw data is loaded directly into the target system for processing. |
Performance Bottlenecks | Transformation can become a bottleneck if the server handling the process lacks resources. | Dependent on the computational power of the target system for transformation. |
Security & Compliance | Sensitive data is transformed before loading, providing higher security compliance. | Sensitive data is loaded before transformation, which could pose security risks if not properly managed. |
Error Handling | Easier to manage data quality issues and handle transformation errors before data reaches the target system. | Error handling and data validation occur post-load, making data quality issues harder to resolve. |
Use of Compute Resources | Requires separate compute resources for transformation (ETL servers or dedicated hardware). | Leverages the computational resources of modern data warehouses (e.g., cloud storage) for transformations. |
Latency | Higher latency due to the transformation step occurring before loading. | Lower latency in loading data, as the transformation happens after the data is already available. |
Data Duplication | Minimizes data duplication as transformed data is loaded into the final format. | Potential for data duplication since raw data is loaded first, and transformation occurs later. |
Data Storage Costs | Requires more space for transformed data, but typically less raw data storage. | May require more storage space due to loading raw, untransformed data. |
Workflow Complexity | Requires pre-built workflows and data pipelines, which are often rigid and predefined. | Offers dynamic workflows with flexibility, particularly in cloud-native environments where automation tools are available. |
Integration with AI/ML | Limited integration with real-time AI/ML applications due to the time-consuming transformation process. | Seamless integration with AI/ML tools as data is available in near real-time for model training and prediction. |
Real-time Integration Support | Not suitable for real-time data ingestion and processing; better for batch jobs. | Well-suited for real-time or near real-time integration with analytics systems. |
Choosing the Right Approach
When deciding between ETL and ELT, consider the following factors:
Data Structure: If your data is well-structured and schema-defined, ETL might be the better choice. If your data is unstructured or semi-structured, ELT might be more suitable.
Processing Requirements: If you need real-time data processing, ELT is the better option. If you can afford batch processing, ETL might be sufficient.
Data Volume: If you have large volumes of data, ETL might be more scalable. If you have smaller data sets, ELT might be more cost-effective.
Data Quality: If data quality is paramount, ETL might be the better choice. If you can compromise on data quality, ELT might be sufficient.
ETL and ELT, both, are viable data integration approaches, each with its strengths and weaknesses. By understanding the differences between these approaches and considering your organization’s specific needs, you can make an informed decision about which approach is best suited for your data integration requirements. Whether you choose ETL or ELT, the key to successful data integration lies in careful planning, execution, and ongoing maintenance.
Contact us for more information on how Dflux can help you with your data integration tasks.
Leave a Reply